Apache Spark is straight-forward to use when there are large files that need to be chunked up and read, but what about when you have many small files? In this post we’ll look at a way to address many small files and some parameter tuning to speed that up.
The sample data we’ll be looking at is the Million Song Dataset(MSD), the entire dataset is about 273 GB, more than enough for Spark to take a bite out of. (If you wish to try this at home the site offers a sample of 10,000 songs at a more digestible size of 1.8GB.) The entire dataset can be downloaded in 26 A-Z partitions, each partition contains between 38,109 and 39,100 songs. Each of these songs is stored as a file in the HDF5 format and is between 180kb to 900kb in size, much too small to split up for a Spark job. The small file size is the crux of our problem.
So we need to make large files, this will be as lists of all the files. It is these lists that will be partitioned among Spark jobs. A job will read the file list and extract important song information in the HDF5 files and aggregate it into larger CSV files which Spark will consume. To create a CSV for every partition:
#!/bin/bash
for X in {A..Z}
do
ls -1 ${X}/*/*/*.h5 > ${X}_file_list.csv
doneFrom each file in the file list, we want to aggregate the relevant information. A script that extracts the title, artist name, and year follows. For reading the MSD HDF5 files there exists a library which makes the reading easier: hdf5_getters.py. It’s referred to as mill below.
import glob
import re
import sys
from functools import partial
from pyspark import SparkConf, SparkContext
import hdf5_getters as mill
# simple wrapper for the hdf5_getters, just be sure the string 'func' exists
def call_mill(m, func, fi):
return getattr(m, 'get_' + func)(fi)
# gather 'fcns' attributes and return them as a comma separated string.
def parse_h5(file_path, fcns):
# read the file
fi = mill.open_h5_file_read('/home/ubuntu/' + file_path)
vals = []
str_format = []
sep = '\t'
# for each getter in fcns
for f in fcns.value:
format = f['format']
str_format.append(format)
val = call_mill(mill, f['func'], fi)
# if string, cast it to utf-8 string
if format == '%s':
# there's a better way to do this but we have to import numpy
if str(type(val)) == "<class 'numpy.ndarray'>":
val = ','.join([x.decode('utf-8') for x in val])
else:
val = val.decode('utf-8')
val = re.sub(r'\t', ' ', val)
vals.append(val)
# close the file
fi.close()
return (sep.join(str_format) % tuple(vals))
def get_headers(fcns, sep='\t'):
headers = []
for f in fcns:
headers.append(f['func'])
return sep.join(headers)
if __name__ == '__main__':
start_letter = None
length = None
if len(sys.argv) < 4:
print('Expected arguments: start_letter, length, workers')
exit(1)
file_prefixes = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
start = file_prefixes.index(start_letter)
end_letter = file_prefixes[start+length-1] # -1 for inclusive
conf = SparkConf() \
.setMaster('spark://spark_ip') \
.set('spark.hadoop.validateOutputSpecs', False) \
.setAppName('h5_to_csv:%s to %s' % (start_letter, end_letter))
sc = SparkContext(conf = conf)
# the fields to get from the hdf5 files
get_fcns = [
{'func': 'title', 'format': '%s'},
{'func': 'artist_name', 'format': '%s'},
{'func': 'year', 'format': '%d'},
]
# let the workers know about them
fcns = sc.broadcast(get_fcns)
# get all file listings
file_list = glob.glob('file_lists/*.csv')
file_list.sort() # alphabetize
job_list = file_list[start:start+length]
# concatenate the file lists
files = sc.textFile(','.join(job_list)).cache()
# process and collect the data from all the files
rdd_output = files.map(partial(parse_h5, fcns=fcns)).collect()
# write the aggregated data as csv.
outname = 'entries-%s-%s.csv' % (start_letter, end_letter)
with open('results/' + outname, 'w') as fi:
fi.write(get_headers(get_fcns) + '\n')
fi.write('\n'.join(rdd_output))
If we zip our dependencies and run this on a cluster with something like:
spark-submit --py-files dep.zip h5_to_csv.py A B 4 # start, end, workersThe results will be underwhelming. If we go to the Spark dashboard and watch the jobs run we’ll see a performance bottleneck because the data is partitioned across only one or two partitions. This is due to the many small file sizes. Per the Spark RDD Programming Guide:
“typically you want 2–4 partitions for each CPU in your cluster.”
Let’s say the cluster is 4 cores, we should want about 8–16 partitions however we’re not seeing that due to size of the files that are being read from the file lists. We can force a number of minimum partitions with the minPartitions argument, changing the files = sc.textFile(...) line to be:
files = sc.textFile(','.join(job_list), minPartitions=8).cache()When working with this many small files 8 partitions still presents a bit of a bottleneck. A better minPartitions can be found by doing some timed runs with a multiplier variable m.
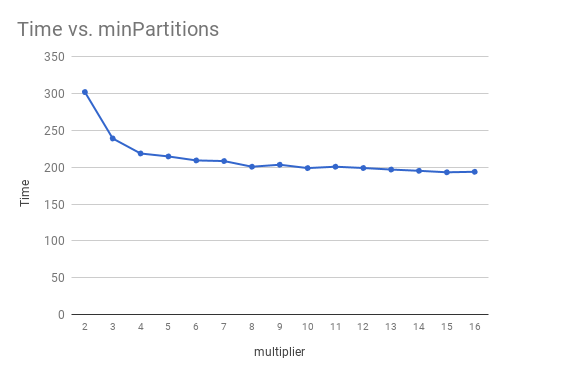
minPartitions = workers * cores * mAs the graph below shows a multiplier of 8 seems reasonable with diminishing returns thereafter. Unless there are any other common bottlenecks there will be noticeably better performance. With six workers, and m = 8 the entire 273 GB can is processed in roughly 24 minutes! On the cluster I was using this is minPartitions=256.
Cluster
The cluster itself setup and run on the Swedish National Infrastructure for Computing (SNIC). In total the cluster consisted of seven nodes with eight CPU’s and 16 GB of RAM each. One of these was the dedicated master node responsible for resource allocation while the remaining six where pure worker nodes, using all their CPUs for data processing.